Gpipe: Easy Scaling with Micro-Batch Pipeline Parllelism
GPipe: 2018년 Google AI Research Division에서 publish한 논문
tensorflow 구현체 (https://github.com/tensorflow/lingvo/blob/master/lingvo/core/gpipe.py)
pytorch 구현체 (https://github.com/kakaobrain/torchgpipe)
Introduction: What is Gpipe?
(1) 문제 제기
- 모든 모델이 그러한 것은 아니지만, Imagenet에서 대체로 모델의 크기가 크면 클 수록 성능이 좋았음.
- Translation에서도 model size의 증가는 번역 품질의 향상으로 이어졌음.
- 크기가 작은 모델의 경우 single accelerator에 model을 올릴 수 있었기 때문에 학습에 큰 어려움이 없었음.
- 하지만, 크기가 큰 모델의 경우, single accelerator에 memory limitation으로 인해 model을 올리기 어렵기 때문에, model parllelism을 이용해 분산 학습을 수행해야 함.
- 효율적인 model parallelism 알고리즘은 디자인과 구현이 어렵고, 효율적인 model parallelism 알고리즘은 task-specific하곤 했음.
(2) GPipe란?
- 위와 같은 model parellism의 어려움을 해결하기 위해 구현된 framework
- 특정 task나 architecture에 종속되지 않음.
- Image Classification과 Machine Translation에 효율적임.
Algorithm
Pipeline Model Parallelism
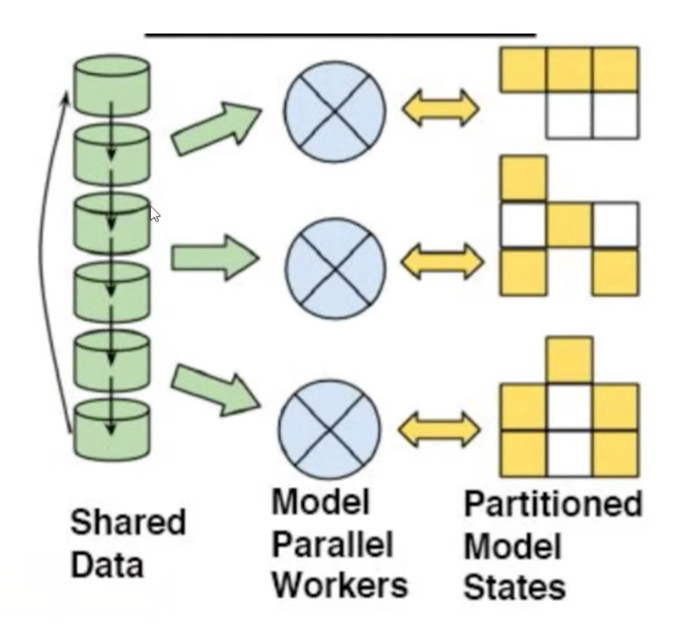
- model parallelization은 sequential하게 분리된 모델을 각각의 parallel worker에 등록해 학습하는 것이다. 당연한 말이지만, 앞선 worker의 연산 결과가 도착하기 전까지 다음 worker는 학습을 할 수 없다.
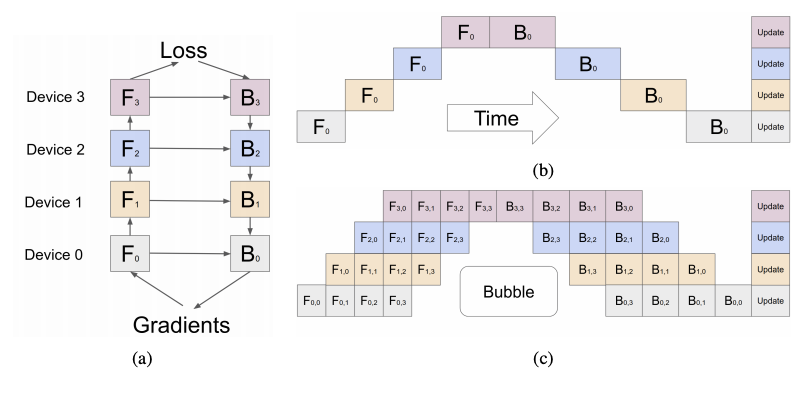
- 이로 인해 (b)와 같이 multiple worker를 효율적으로 사용하지 못하는 문제가 발생하는데, (c)와 같이 mini-batch를 micro-batch단위로 쪼개어 연산 속도를 증진시키자는 것이 핵심 아이디어다.
필자의 생각: BatchNorm을 이용했을 때 데이터 해저드가 발생할 수 있을 것 같다.
Re-materialization
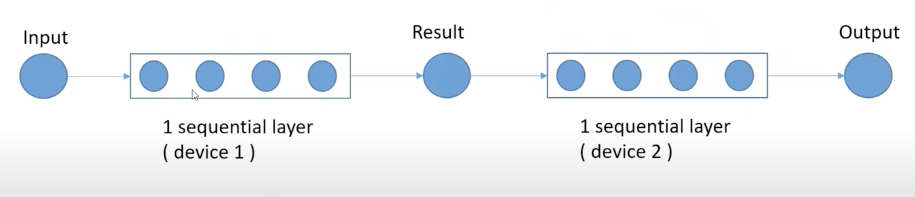
- 본래, 역전파를 위해 각 layer별 input을 저장하고 있었어야 하나, 모든 layer의 input을 저장하는 것은 메모리를 많이 차지하는 문제가 발생함.

- 이에, sequential layer의 input만을 저장하고 있고, 그 안의 세부 layer의 input값은 backward 단계에서 계산하여 사용하자는 것이 핵심적인 아이디어다. memory는 크게 줄일 수 있으나, 연산량이 증가한다는 단점이 존재한다.
- 논문 저자의 실험에 따르면, Amoebanet(82M의 파라미터를 가진 모델)에 대해서 실험을 했을 때 6.26GB에서 3.46GB로 메모리를 크게 절감하는 효과를 얻을 수 있었으나, 25%의 계산 시간이 더 소요됐다고 한다.
- Without rematerialization
- Space Complexity: ${O (N \times L)}$
With rematerialization
- Space Complexity: ${O (N + L/K \times N/M)}$
L: 레이어 수, K: 파티션 수, N: mini-batch의 크기, M: 디바이스의 숫자
Perfomance Optimization
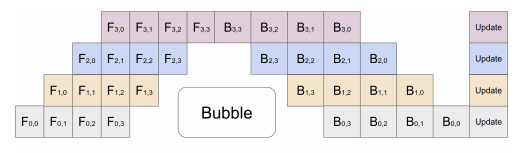
- 그림에서 볼 수 있듯이 Bubble이 발생하는데, 논문 저자의 말에 따르면, Bubble Overhead의 수식은 \({O({K-1}/{M+K-1})}\)인데, M이 4K보다 크면 무시할 수 있다고 한다.
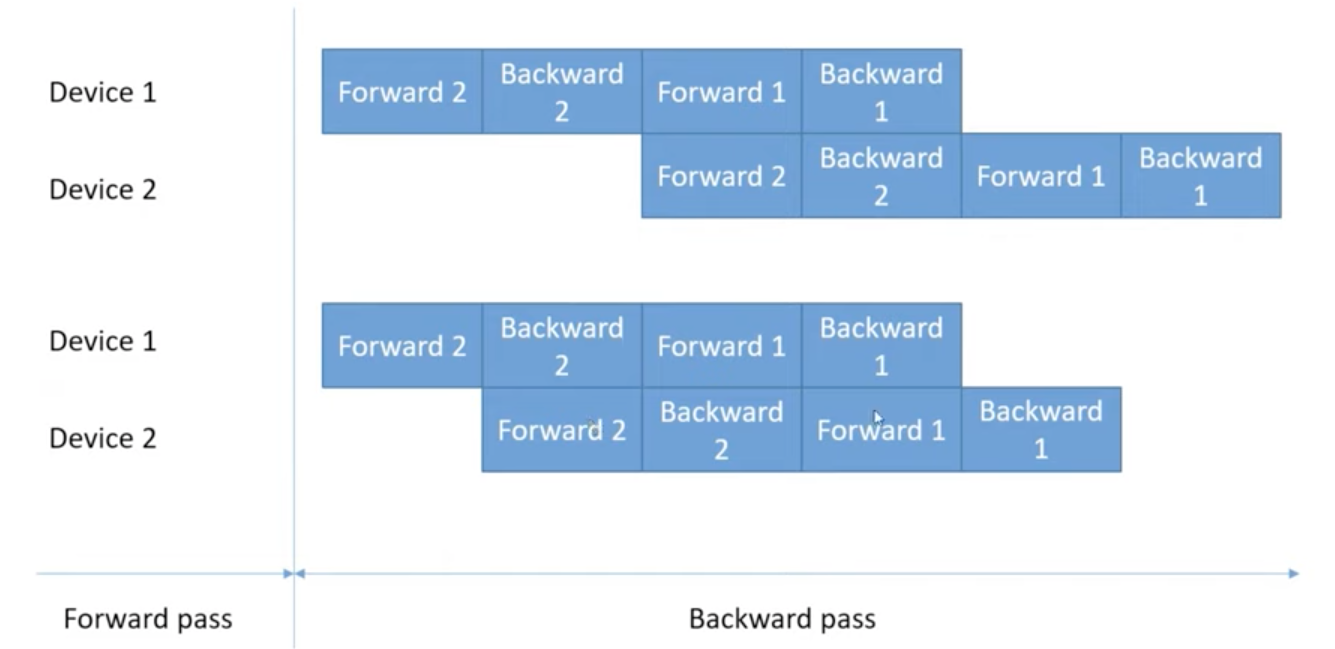
- Rematerialization을 적용하면 Backward를 적용하기 위해 Forward를 먼저 계산해야 하는데, pararellize할 수 있는 Forward 계산은 병렬로 수행할 수 있도록 scheduling하여 연산 시간을 줄일 수 있다고 한다.
